Что означает машинное обучение
Машинное обучение, или machine learning, относится к области искусственного интеллекта. Его задача - построить модель, которая учится на данных. Модель получает примеры, ищет повторяющиеся связи и выдает прогноз, оценку или рекомендацию для новых объектов.
Обычная программа работает по заранее записанным правилам: если сумма заказа больше 5 000 ₽, показать бесплатную доставку. ML-система получает много прошлых заказов и сама находит признаки, связанные с покупкой: источник перехода, устройство, время суток, состав корзины, скидку, повторный визит. Потом она оценивает новый заказ и сообщает вероятность оплаты.
Такой подход используют там, где ручных правил слишком много или они быстро устаревают: антиспам, рекомендации товаров, прогноз спроса, скоринг клиентов, распознавание речи, модерация контента, оценка рекламного трафика. Но ML не заменяет здравый смысл. Если данные собраны плохо, модель уверенно повторит ошибки исходной базы.
Как работает машинное обучение
Внутри почти любой ML-задачи есть несколько шагов. Сначала собирают примеры. Для интернет-магазина это заказы, визиты, товары и возвраты. Для рекламной аналитики - кампании, площадки, расходы, клики, события после клика и результат.
Затем данные превращают в признаки. Признак - это свойство объекта, которое может влиять на прогноз: цена товара, категория, канал перехода, день недели, глубина просмотра, тип устройства, формат рекламного поста. Хорошие признаки описывают ситуацию так, чтобы модель могла сравнивать похожие случаи.
После этого модель обучается. Она перебирает варианты внутренних настроек и проверяет, насколько ее ответы совпадают с известным результатом. Если модель предсказывала покупку, а человек ушел без заказа, ошибка растет. Если прогноз совпал с фактом, настройка получает больше веса.
Финальный шаг - проверка на данных, которые модель не видела во время обучения. Без такой проверки легко получить красивую цифру в отчете и слабую пользу в работе. Модель могла запомнить старые примеры, но не научиться обобщать новые.
Есть 10 000 прошлых заявок. В каждой строке указаны источник, стоимость клика, устройство, город, время визита и факт продажи. Модель видит, что вечерние переходы из одного канала часто дают заявки, но продажи редки. Другой канал приводит меньше кликов, зато чаще дает оплату. Для следующей кампании модель оценивает вероятность полезного результата по каждому источнику.
Какие бывают виды машинного обучения
Обучение с учителем
У каждого примера есть известный ответ: купил или не купил, спам или обычное письмо, лид качественный или нет. Модель учится связывать признаки с этим ответом. Сюда относятся классификация и регрессия.
Обучение без учителя
Готового ответа нет. Модель ищет группы, похожие объекты и аномалии. Так можно разделить клиентов на сегменты, найти необычные клики или увидеть товары, которые покупают вместе.
Обучение с подкреплением
Система выбирает действие и получает награду или штраф. Так обучают игровые стратегии, роботов, рекомендательные механики и некоторые системы управления ставками.
Глубокое обучение
Это семейство методов на основе нейронных сетей. Их применяют для текста, изображений, речи, видео и задач, где признаков очень много и часть связей трудно описать вручную.
Где машинное обучение встречается в обычной работе
ML давно вышел за пределы лабораторий. Почтовый сервис сортирует спам, маркетплейс рекомендует товар, банк оценивает риск кредита, навигатор прогнозирует время в пути, видеосервис подбирает ролики, CRM отмечает лиды с высокой вероятностью сделки.
В маркетинге машинное обучение часто работает рядом с метриками, которые уже есть в отчете. Например, модель может предсказывать вероятность заявки после клика, находить похожие аудитории, оценивать риск оттока, выбирать товар для письма, распределять бюджет между объявлениями или отмечать трафик, который требует ручной проверки.
Но модель не умеет догадаться о том, чего нет в данных. Если в отчете указано только 3 000 кликов без привязки к источникам, она не узнает, какие переходы пришли из Telegram-канала, какие из VK-группы, а какие от блогера. Для ML нужна история с нормальными связями: источник, действие, стоимость и результат.
Как машинное обучение связано с Trafstat
Рекламодатель часто хочет получить от ML ответ до следующей закупки: где выше шанс заявки, какая площадка дает живые переходы, какой формат стоит повторить. Такой прогноз начинается с аккуратной истории размещений. Если один адрес поставили сразу в Telegram, MAX, VK, рассылку и пост блогера, дальнейшая аналитика видит общий поток и теряет источник.
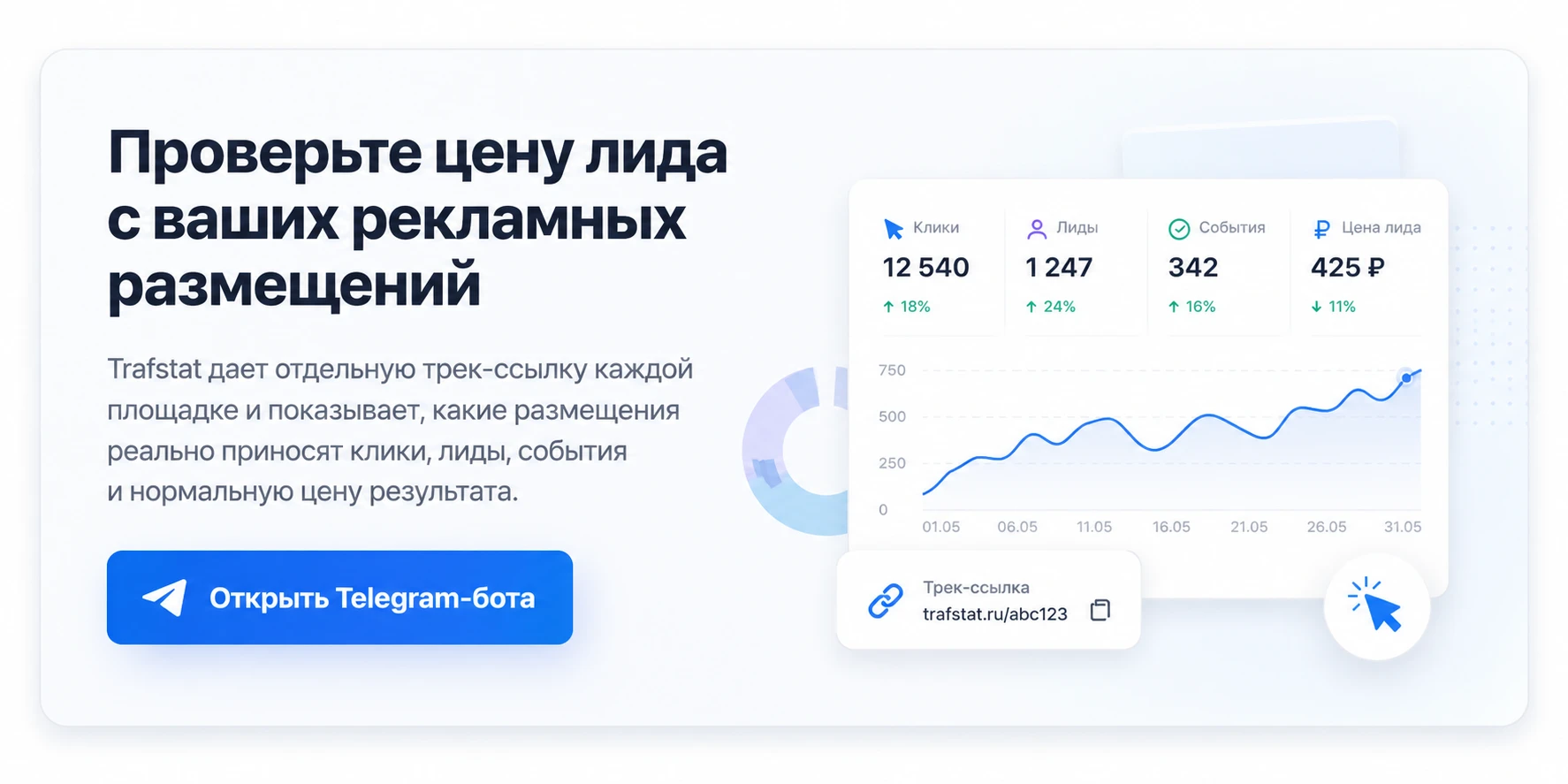
Методика Trafstat строится вокруг другой записи данных: одна кампания, несколько размещений, отдельная трек-ссылка для каждого размещения, клики, события и стоимость результата. Для человека это удобный отчет. Для будущих ML-моделей это набор связей, где видно, какой источник привел переход, что произошло после клика и во сколько обошелся результат.
Например, два канала могут дать одинаковый CPC - по 45 ₽ за переход. Первый приводит много коротких визитов без формы, второй дает меньше кликов, но чаще приводит к заявке. Если собирать только клики, модель сделает слабый вывод. Если хранить события после клика, стоимость лида, дату, формат поста и ссылку публикации, этот набор помогает оценивать похожие запуски.
Trafstat не обещает угадать результат рекламы заранее. Его роль ближе к подготовке нормальной базы опыта: зафиксировать, откуда пришел человек, что он сделал после клика и как это соотносится с расходом на размещение. На такой базе можно строить правила, отчеты и осторожные прогнозы без смешивания источников.
Где машинное обучение ошибается
ML-система не понимает мир сама по себе. Она опирается на обучающие примеры и цель, которую ей задали. Если цель выбрана плохо, модель будет оптимизировать не тот результат. Например, она может искать дешевые клики, хотя бизнесу нужны оплаты, повторные покупки или заявки от компаний с нужным бюджетом.
Вторая причина ошибок - смещение данных. Если модель обучали на прошлогодних кампаниях, где работал один оффер, она может плохо оценить новый рынок, новый канал или другой продукт. Похожая проблема возникает, когда в истории нет провалов: команда сохраняет только удачные кейсы, и модель не видит, какие признаки связаны с потерей бюджета.
Третья причина - утечка данных. В обучение случайно попадает признак, который известен только после результата: статус сделки, финальная сумма, ручная отметка менеджера. На тесте модель выглядит сильной, а в реальной работе теряет качество, потому что этот признак заранее недоступен.
Четвертая причина - автоматическое доверие к оценке. Вероятность 72% не означает гарантию. Это только расчет по данным и заданной метрике. Для рекламных решений его лучше читать рядом с расходом, качеством источника, объемом выборки и свежестью примеров.
Как подойти к машинному обучению без лишней математики
Если вы не собираетесь писать модели сами, начните с вопросов к данным. Какой результат считать целевым: клик, заявку, продажу, повторную покупку, удержание? Какие признаки доступны до решения? Где данные смешиваются? Какие события нужно начать фиксировать сегодня, чтобы через месяц сравнить источники?
Для рекламной команды базовый минимум выглядит так: отдельная ссылка для каждого размещения, расход, дата выхода, формат поста, креатив, клики, уникальные переходы, события после клика, лиды и дальнейшая судьба заявки. Такой набор уже помогает принимать решения вручную и позже пригодится для модели.
После сбора данных не спешите обучать нейросеть. Часто хватает таблицы, правил и нескольких графиков: какой канал дает дешевый переход, где выше CR, где растет отказ, какие блогеры дают заявки по похожей цене. Машинное обучение имеет смысл, когда примеров стало достаточно, а ручное сравнение уже не успевает за числом источников.
Хорошая подготовка к ML выглядит скучно: единые названия кампаний, одинаковые правила учета, сохраненные ссылки публикаций, проверка дублей, корректные события и ясная цель. Зато такая база дает модели шанс учиться на фактах, а не на каше из кликов.
Частые вопросы
Машинное обучение и нейросети - одно и то же?
Нет. Нейросети - один из методов машинного обучения. В ML есть и другие подходы: деревья решений, линейные модели, ансамбли, кластеризация и поиск аномалий.
Сколько данных нужно для машинного обучения?
Единого числа нет. Для одних задач хватает сотен качественных примеров, для других нужны миллионы событий. Сначала оцените, хватает ли данных для обычного сравнения и не смешаны ли источники.
Что лучше: правила или машинное обучение?
Правила хороши, когда условие легко описать: например, не считать повторный клик одного пользователя новым лидом. ML нужен, когда признаков много и связи между ними меняются.
Можно ли использовать ML в малом бизнесе?
Да, но начинать стоит со сбора данных и отчетов. Если кампаний мало, больше пользы даст аккуратная аналитика источников, а не дорогая модель.
Проверьте цену лида с ваших рекламных размещений